Compressed Plot Farming
As detailed in the plotting section, compressed plots are supported for both plotting and harvesting as of Chia version 2.0. Before you can harvest compressed plots, you need to inform your harvesters of the fact that they exist.
As of Chia version 2.0, decompression must be performed at the harvester level. You therefore will need to apply the settings listed on this page to each of your harvesters individually. This also means that each individual harvester will need to be capable of decompressing the plots that have been installed locally.
In the future, we plan to enable decompression at the farmer level. This means that only one computer on your network will need to be equipped with a fast CPU or GPU for decompressing plots.
Enable compressed plot support
GUI
- Navigate to the
Settingspanel in the lower-left corner of the GUI. - Click the
HARVESTERtab at the top of the panel. The following screen will appear:
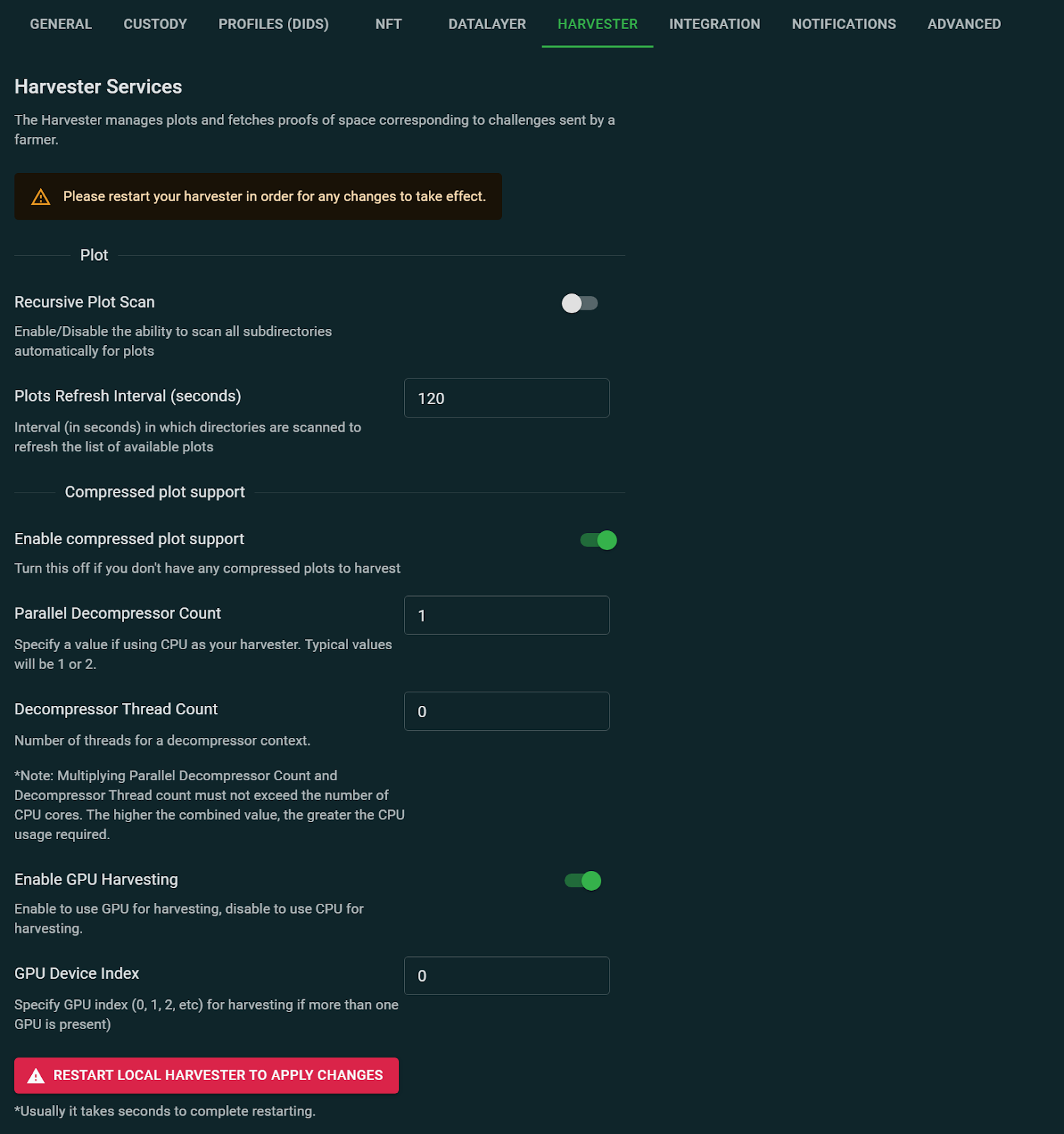
-
Slide the
Enable compressed plot supportslider to the right, as shown in the above image. -
For
Parallel Decompressor Count, the default value of1will be fine for most users. Here are some details:- This number only affects the amount of memory used for decompression.
- The amount memory required will vary according to the level of compression. For example, if
Parallel Decompressor Countis set to1, around 600-700 MB of memory will be consumed while decompressing a single C7 plot. - The amount of memory required will scale linearly, so setting it to
2will double the required memory.
If your harvester has sufficient memory, as well as a high CPU core count, you can increase this number. For example,
2might be optimal for a 16-core CPU, or4for dual 32-core CPUs.However, the generation and speed of your CPU will also have a large impact on the optimal setting. If you do increase
Parallel Decompressor Count, be sure to monitor your harvester's performance as there is no one-size-fits-all solution. -
The default value for
Decompressor Thread Countis0. This is the number of threads that will participate in decompressing plots. This number, multiplied byParallel Decompressor Count, needs to less than or equal to the total number of harvester cores.
For example, if your harvester has one CPU with eight cores, you might use the following settings:
_ Parallel Decompressor Count: 1
_ Decompressor Thread Count: 6
This would instruct the harvester process to use six of the eight cores for decompressing plots, and to use the remaining cores to run the OS, etc. 5. If you want to use a GPU for harvesting, slide the Enable GPU Harvesting slider to the right, as shown in the above image. Note that in order to use this setting, your harvester must have an NVIDIA CUDA-class GPU. For harvesting C7 plots, 600-700 MB of DRAM is required. 6. If your harvester has multiple GPUs, you can use GPU Device Index to choose which one to use. If your harvester only has one GPU, then leave this set to 0.
After all of these settings have been properly set, click the red RESTART LOCAL HARVESTER TO APPLY CHANGES button. After your harvester restarts, it will use the updated settings.
CLI
All of the new harvester settings live inside ~/.chia/mainnet/config/config.yaml.
If you have never installed Chia on this harvester, config.yaml won't exist. In this case, run the following command to generate a new copy:
chia init
If you have previously installed Chia on this computer, then config.yaml likely already exists. In this case, you will need to add several new settings. However,
- If you run
chia initwhen the config file already exists, Chia won't make any modifications. - If you delete
config.yamland runchia init, the new settings will be added, but you will lose any custom changes you previously made.
In the case where config.yaml already exists, you therefore are recommended to do the following:
- Edit
config.yaml - Search for
harvester: - From inside this section, add the following parameters, which include the default settings:
parallel_decompressor_count: 0
decompressor_thread_count: 0
use_gpu_harvesting: false
enforce_gpu_index: false
gpu_index: 0
decompressor_timeout: 20
disable_cpu_affinity: false
max_compression_level_allowed: 7
At this point, regardless of whether you are upgrading or running a new build of Chia on this harvester, your copy of config.yaml contains all of the latest settings. Their definitions and recommended values are as follows:
parallel_decompressor_count: The number of CPUs to be used for decompressing plots. If this is set to0, then harvesting of compressed plots will be disabled. For GPU harvesting, set this value to1. For CPU harvesting, set it to the number of CPUs you want to use for decompression (typically1).decompressor_thread_count: The number of CPU threads that will participate in decompressing plots. This number multiplied byParallel Decompressor Countneeds to less than or equal to the total number of CPU cores.use_gpu_harvesting: Set totrueto enable harvesting with a GPU. Note that in order to use this setting, your harvester must have an NVIDIA GPU with CUDA capability 5.2 and up, with at least 8GB of vRAM.gpu_index: If your harvester has multiple GPUs, use this setting to choose which one to use. If your harvester only has one GPU, then leave this set to0.enforce_gpu_index: Set totrueif your harvester has more than one GPU and you want to use one other than the default of0.decompressor_timeout: The number of seconds for your decompressor to time out. The default value of20is typically fine.disable_cpu_affinity: This should typically befalse. When it isfalse, when using multiple CPU decompressors, each with multiple threads, the threads for each decompressor will be assigned to different physical CPUs. This prevents them for competing over compute time. If it is set totrue, the threads for each decompressor will be assigned to the same CPU.max_compression_level_allowed: The highest level of compression your harvester will support. In Chia version 2.0, the maximum level is7. This will likely be increased in the future, but for now, you cannot increase it beyond the default. You can, however, set it to a lower number if desired.
After you have finished making these updates, save config.yaml and restart your harvester by running the following command:
chia start harvester -r
Your new settings will be applied.